Differentiable rendering is the future
What does a rendering engine of the future look like?
A future real time renderer should produce images that are indistinguishable from real photos. The produced images should be, visually, up to the standard of images captured with cinema cameras.
Tap/hover to play
Better graphics require exponentially more work
From the start, in computer graphics, researchers and artists have put their aim on producing photorealistic images. At each milestone, we were first amazed, then, eventually, got attuned to the synthetic images and started spotting the flaws. I remember playing the Battlefield Bad Company 2 campaign in 2010 and telling myself that we have achieved real time photorealistic results. Looking back at this game today in 2022, I am astonished to ever have thought it looked like real life.

Through the years we have gotten better at discerning fake computer-generated images from real images. Consequently, rendering photorealistic images now takes more artist work, more accurate rendering algorithms and more computation power/memory. In 2008, it took three years to develop GTA V (see GTAV). While more recent games like Red Dead Redemption 2 took over eight years (see RDR2).
Sometimes newer games do not even have more content because it takes so much artistic and engineering effort to meet the new standard of visual quality.
It is common for smaller studios to use one of the existing rendering engines and ready-made assets or go for alternative looks, where photorealism does not matter like the cartoonish look.
In essence:
- With better graphics, we get better at spotting the differences with real life.
- Improved graphics require higher quality assets.
- At each graphical improvement, the shortcomings are more subtle. It is harder to consciously understand and fix the flaws.
At the current state of rendering:
- For existing objects, geometry and texture can be captured but material requires manual artist work.
- For non-existing objects, geometry, texture, and material require manual artist work.
- More complex appearance/light interaction and higher number of polygons will take longer to render.
Higher quality assets and thus better graphics will, currently, require exponentially more manual artist work and take more time to render.
What a future rendering engine should do to attenuate these issues:
- Let the artist express their intent to the furthest point possible and automatize the last step to reach photorealism.
- Make complexity of appearance/light interactions and number of polygons more independent of render time.
Better graphics with less work
A future rendering engine should be able learn to produce photorealistic images without requiring an army of artists manually adding tiny little specks of dusts on tree leaves to run after photorealism.
Ideally, artists only wish to work down to a certain level. For example, "I want this sword to have this old, rusted steel look and reflect the sunlight on the camera" The artist might want to control where the rust is, at the lowest level, but not necessarily fine tune the details of the rust so that it looks photorealistic. In other words, artists should keep their expressiveness but avoid the slow back-and-forth process of fine tuning a scene to meet photorealism.
Additionally, the rendering time should not depend on the complexity of light interactions in the scene. For example, materials like the human skin currently require a longer time to render because of the subsurface scattering of light near the surface. Mimicking these complex light interactions is either done in brute force or with complex algorithms. The problem is that the first is terribly slow and the second is faster but not scalable. Ideally, rendering a scene should consist of doing the (same) simplest possible task for each ray for the process to scale well performance-wise with parallelization.
To summarize, a future rendering engine should:
- Be optimizable towards producing photorealistic images given a base representation which captures all artistic intent.
- Represent all light interactions with the same algorithm so that rendering images stays extremely scalable.
Differentiability
For a rendering engine to be optimizable towards photorealism, one approach is to make the renderer and scene representation differentiable. This means that the rendered images can be compared to a target distribution and then backpropagate gradients through the renderer to tune the scene. Where the target distribution is described by a dataset of real images.
This is the reason differentiable rendering is one of the key elements to solve the never-ending race towards photorealism.
Additionally, it can open the door to expressing the rendering of a scene through a single architecture (MLPs for example), which makes the rendering algorithm simpler and scales better long term (with more parallelism).
Animations
While I have mostly been talking about rendering static scenes (with dynamic lighting), we can see how differentiability could extend to animations. Perfecting an animation to look real and not robotic or uncanny.
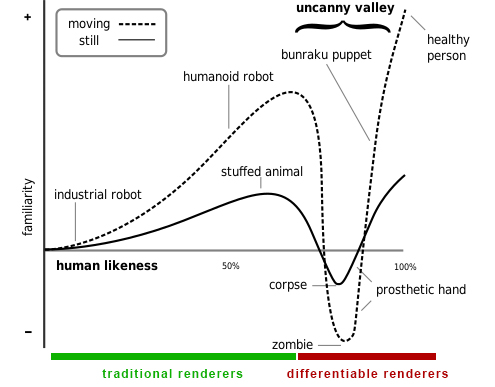
Photorealistic computer animations can sometimes provoke uncanny feelings since they look so close to real life but lack subtle details that we unconsciously notice. Differentiable rendering could allow optimization based on photorealistic video footage and thus bridge the synthetic and real world.